Sang Jun Kim1, Young Kyu Lee2, Joon Hyo Rhee2, Juhyun Lee2, Gyeong Won Choi2, Ju-Ik Oh2, Donghui Yu1†
1Department of Computer Information Engineering, Catholic University of Pusan, Busan 462527, Korea
2Time and Frequency Group, Korea Research Institute of Standards and Science, 267 Gajeong-Ro, Yuseong-Gu, Daejeon 34113, Korea
†Corresponding Author: E-mail, dhyu@cup.ac.kr Tel: +82-051-510-0643 Fax: +82-051-510-0658
Citation: Kim, S. J., Lee, Y. K., Rhee, J. H., Lee, J. H., Choi, G. W., Oh, J.-I., & Yu, D., 2024, Development of Machine Learning Model to Predict Hydrogen Maser Holdover Time, Journal of Positioning, Navigation, and Timing, 13, 111-115.
Journal of Positioning, Navigation, and Timing (J Position Navig Timing) 2024 March, Volume 13, Issue 1, pages 111-115. https://doi.org/10.11003/JPNT.2024.13.1.111
Received on Feb 04, 2024, Revised on Feb 23, 2024, Accepted on Feb 26, 2024, Published on Mar 15, 2024.
License: Creative Commons Attribution Non-Commercial License (https://creativecommons.org/licenses/by-nc/4.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
This study builds a machine learning model optimized for clocks among various techniques in the field of artificial intelligence and applies it to clock stabilization or synchronization technology based on atomic clock noise characteristics. In addition, the possibility of providing stable source clock data is confirmed through the characteristics of machine learning predicted values during holdover of atomic clocks. The proposed machine learning model is evaluated by comparing its performance with the AutoRegressive Integrated Moving Average (ARIMA) model, an existing statistical clock prediction model. From the results of the analysis, the prediction model proposed in this study (MSE: 9.47476) has a lower MSE value than the ARIMA model (MSE: 221.2622), which means that it provides more accurate predictions. The prediction accuracy is based on understanding the complex nature of data that changes over time and how well the model reflects this. The application of a machine learning prediction model can be seen as a way to overcome the limitations of the statistical-based ARIMA model in time series prediction and achieve improved prediction performance.
time comparison, time synchronization, deep learning, holdover
위성항법시스템(Global Navigation Satellite System, GNSS), 모바일 네트워크, 인터넷 통신 등에서 시각 동기화 기술은 핵심적인 역할을 한다. 시각 동기화 기술은 일반인이 인지하기는 어려우나 일상생활의 기반이 되는 국가 표준시, 자율주행, 기계제어, 건설 현장, 이동통신, GNSS 위치 기반 서비스 등의 원천 기술이다.
기존의 시각 동기화 연구는 주로 GPS와 같은 위성항법시스템에 초점을 맞추었다 (Yu 2017, Yu & Hwang 2018, Piccolomini et al. 2019, Shahvandi & Soja 2021, Kanhere et al. 2022). 그런데 이러한 방법들은 도심 지역에서의 고층 건물이나 자연 장애물로 인한 신호 차단 및 왜곡과 같은 환경적 영향에 취약하다. 이로 인해 시간 동기화의 정확도와 신뢰성에 영향을 미치는 문제가 발생한다. 최근에는 머신러닝 및 딥러닝 기술을 활용하여 이러한 한계를 극복하려는 연구가 증가하고 있으며 (Semanjski et al. 2020, Ozeki & Kubo 2022), 특히 시계의 특성 데이터를 분석하고 이를 기반으로 한 안정적인 시각 동기화 기술 개발에 대한 필요성이 커지고 있다 (Yu & Kim 2022). 그러나 국내외적으로 시계의 특성인 잡음이나 특별히 수소 메이저의 멈춤으로 메이저 간의 통신이 끊어져 동기를 잃어버리는 Holdover 상황 등을 반영하여 데이터를 분석하고 이를 머신러닝 및 딥러닝 기법을 적용하여 안정화하는 기술이 보고된 사례가 희박하다.
이에 따라 본 논문은 시계에 최적화된 머신러닝 모델을 구축하여 원자시계의 잡음 특성을 반영한 안정적인 시각 동기화 기술을 확보하고 항법신호를 이용한 시각비교기법에 적용하며, 그 성능을 기존 시계열 예측을 위한 통계적 모델인 AutoRegressive Integrated Moving Average (ARIMA)와 비교한다.
UTC는 1972년부터 시행된 국제 표준시로, 세슘 원자의 진동수를 기반으로 하여 매우 높은 정확도를 가진다. UTC의 생성은 국제원자시와 윤초 보정을 기반으로 표준화되며, 국제도량형국(Bureau International des Poids et Mesures, BIPM)의 관리 하에 세계 각국의 시간 표준 연구실의 원자시계들과 GNSS 위성, 통신위성을 통해 서로 비교 측정된 데이터를 기반으로 한다. UTC(k)는 국가 또는 해당 연구기관을 나타내는 코드로, 한국표준과학연구원(Korea Research Institute of Standards and Science, KRISS)의 경우 ‘KRIS’로 표현된다. UTC(k)의 생성 과정에는 Modified Julian Date (MJD)를 기반으로 하며, MJD가 4와 9로 끝나는 날 0시 UTC에 시계들을 비교 측정한다. 이 데이터는 한 달 간 모아져 BIPM에 제출되며, BIPM에서는 ALGOS 알고리즘을 통해 분석한 후 매달 Circular T를 통해 [UTC-UTC(k)] 결과를 발표한다. UTCr, 즉 ‘빠른(rapid) UTC’는 매일 측정된 시각비교 데이터를 바탕으로 만들어지며, 매주 [UTCr-UTC(k)] 결과가 발표된다.
국제 표준시의 생성을 위한 시계열 데이터 예측 모델들은 시간에 따라 변하는 데이터의 패턴을 분석하고 미래를 예측하는 데 중요한 도구이다. 이러한 모델 중 대표적인 통계적 모델인 ARIMA는 자기회귀(AR), 차분(I), 이동 평균(MA)의 세 가지 주요 구성 요소를 결합하여 시계열 데이터의 패턴을 분석한다.
Lee et al. (2020)에서는 KRISS에서 운영 중인 두 대의 수소메이저(H6, H8)가 10일 후에 어떠한 값을 나타낼 것인지 ARIMA 모델을 통해 예측하고, 이를 BIPM에서 발표하는 [UTCr-UTC(k)] 결과와 비교함으로써 예측의 정확도를 검증하였다 ARIMA 모델을 적용한 [UTCr-Hn] pred – [UTCr-Hn] real의 최대 잔차폭은 H6: 6.1 ns, H8: 6.2 ns였다. 이는 기존 UTCr-UTC(KRIS)가 최대 잔차폭이 약 37 ns 대비, 약 6배 가량의 성능 향상을 확인할 수 있었다.
본 논문에서는 데이터의 내재된 구조를 학습하는 데 유용한 Self Supervised Learning 기법 (Gui et al. 2023)을 적용하여 RNN 기반의 LSTM, GRU 레이어와 Dense 레이어들을 쌓아 올리는 방식으로 모델 구축하였다. 통계적 모델인 Lee et al. (2020)와 비교를 위해 Fig. 1과 같은 특성을 보이는 MJD 58620 ~ MJD 58720의 수소 메이저 H6의 데이터를 활용하였다.
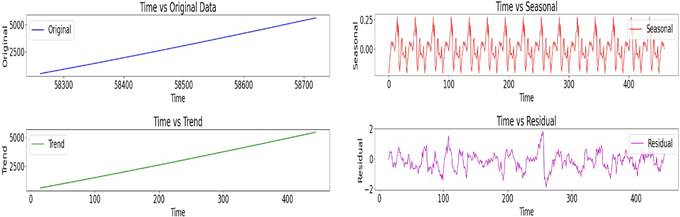
Fig. 1. Analysis of atomic clock data and its trends, seasonality, and residuals.
본 논문에서는 MJD 56260부터 56619까지의 데이터를 학습하고 이후 학습데이터에 사용되지 않은 MJD 58620부터 58720까지를 예측하였으며, 각 시점에 대해 머신러닝 모델의 일반적인 성능 평가기준인 평균제곱오차(Mean Square Error, MSE)로 평가하였다.
LSTM 10 to 1은 10개의 연속된 시간 범위를 입력 받아, 그 다음 1개의 시간 범위의 값을 예측하는 모델이다. LSTM 단일 레이어로 구성하는 것 보다는 Dense 레이어와 조합하였을 때 더 나은 성능을 보였으며, 각 레이어의 뉴런의 개수 역시 최적화된 파라미터가 있다는 것을 확인하였다. LSTM 100 to 10은 100개의 연속된 시간 범위를 입력 받아, 그 다음 10개의 시간 범위의 값을 예측하는 모델이다. 학습 중 그라디언트가 비정상적으로 증가하여 학습이 진행되지 않는 현상을 공통적으로 발견하였다. 이 문제를 개선하기 위해 본 논문에서는 LSTM의 뉴런과 활성화 함수 사이에 배치 정규화(batch normalization)를 적용하였다. 배치 정규화가 적용된 모델의 성능은 Table 1의 LSTM 100 to 10과 같으며, 이 경우 학습은 진행되지만 정상적인 예측을 기대할 수 없었다. GRU 100 to 10은 100개의 연속된 시간 범위를 입력 받아, 그 다음 10개의 시간 범위의 값을 예측하는 GRU 기반의 모델이다. GRU 적용 모델의 경우 학습이 정상적으로 진행되나, 기존 손실함수인 MSE의 특성상 학습 초기의 이상치에 대해 민감하다는 단점이 있었다. 이에 학습 초기에는 이상치에 덜 민감한 MAE를 적용하되 임계 값(delta)에 따라 MSE를 적용할 수 있도록 Huber loss (delta =50)를 적용하여 학습과정을 개선하였다. Fully Connected Network (FCN) 100 to 10은 100개의 연속된 시간 범위를 입력 받아, 그 다음 10개의 시간 범위의 값을 예측하는 Dense 레이어로 구성된 모델이다. 앞선 결과들에서 확인할 수 있듯 시계데이터의 예측에 있어서는 비교적 단순한 모델에서 나은 성능을 기대할 수 있을 것이라 판단하여 적용하였다. 활성화 함수의 사용에 있어서 일반적으로 사용된 Relu보다 간단한 linear가 더 높은 성능을 보임을 확인할 수 있었다.
Table 1. Model configuration and performance evaluation for predicting the operation of H6.
| Prediction model | Model structure | Total MSE |
|---|---|---|
| LSTM 10 to 1 | LSTM single 1000 LSTM single 1000 + Dense 300 LSTM single 3000 + Dense 300 LSTM single 100 + Dense 300 LSTM single 100 + Dense 100 LSTM single 100 + Dense 500 | 2726.747 2.314 8.184 0.836/10.577 42.563 10.577 |
| GRU 100 to 10 | GRU single 1000 + Dense 200 GRU single 300 + Dense 100 GRU single 1000 + Dense 500 GRU 500 + GRU 500 + Dense 500 | 14.769 34.422 27.601 18.640.731 |
| LSTM 100 to 10 | LSTM single 1000 + Dense 300 LSTM single 300 + Dense 300 LSTM single 3000 + Dense 200 LSTM 1000 + LSTM 1000 + DropOut 0.3 + Dense 1000 LSTM 2000 + LSTM 2000 + DropOut 0.3 + Dense 2000 LSTM 2000 + Dense 2000 + DropOut 0.3 | 83283.938 2913926.142 805881.700 35190.731 90784.440 15881197.766 |
| FCN 100 to 10 | Dense 50000 + DropOut 0.3 (linear) Dense 100000 + DropOut 0.3 (linear) Dense 50000 + DropOut 0.3 (Relu) Dense 100000 + DropOut 0.3 (Relu) Dense 50000 + Dense 5000 + DropOut 0.3 (linear) Dense 20000 + DropOut 0.3 (linear) Dense 10000 + DropOut 0.3 (linear) | 3.373 8.795 14.333 18.324 9.763 2.993 4.842 |
Fig. 2는 이 연구에서 머신러닝 모델의 홀드오버 상황을 가정한 지점의 값을 예측하기 위한 방식을 설명한다. 먼저 머신러닝 모델 입력값을 이전 step의 예측값을 활용하여 다음 시간 지점의 값을 생성한다. 이후 k step 예측값을 k+1 step 실측값으로 활용하여 연속적인 예측값 생성하는 방식을 적용하였다.
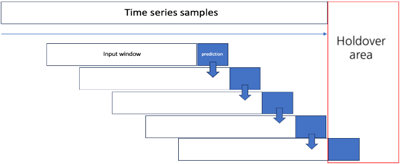
Fig. 2. Prediction method for holdover situation.
딥러닝 모델은 본 논문에서 가장 좋은 성능을 기록한 FCN 100 to 10의 Dense 20000 + DropOut 0.3 (linear) 모델을 사용하였으며, 시간 예측에 있어 동일 시간 지점에 대한 여러 예측 값이 생성되는 경우 첫 시간 지점에서 형성된 값을 사용하였다. 통계모델인 ARIMA의 경우 Lee et al. (2020)에서 제안된 p =0, d=2, q=2 모델을 사용하였다. 딥러닝 모델과 ARIMA 모델은 모두 MJD 58261 ~ 58619를 학습데이터로 제공받아 최종적으로 MJD 58620 ~ 58721, 101개의 타임 스탭에 대해 예측을 수행하였다. 각 모델의 예측 결과는 정답값과의 MSE로 비교하였으며 그 결과는 Fig. 3과 같다.
Fig. 3에서 파란선은 ARIMA 모델에 의한 예측값과 실제값의 차이를 나타내고, 주황선은 딥러닝 예측 모델의 예측값과 실제값의 차이를 나타낸다. 이 논문에서 제안한 예측 모델(MSE: 9.47476, 최대잔차폭: 5.2 ns)이 ARIMA 모델(MSE: 221.2622, 최대잔차폭: H6: 6.1 ns)에 비해 더 낮은 MSE와 최대잔차폭 값을 가지며, 이는 더 정확한 예측을 제공함을 의미한다. 머신러닝 예측 모델의 적용은 시계열 예측에서 통계 기반의 ARIMA 모델의 한계를 극복하고 더 향상된 예측 성능을 얻기 위한 방법으로 볼 수 있다.
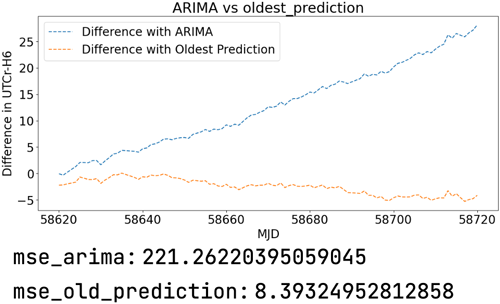
Fig. 3. Performance comparison between statistical-based models and deep learning-based models.
본 연구에서는 수소메이저의 홀드오버 상황에서도 안정적인 시각동기화를 위한 방식으로 머신러닝 기반의 수소메이저 시계열 예측모델을 제안하였다. 제안한 모델은 통계적 모델인 ARIMA에 비해 23.35% 더 낮은 MSE와 0.9 ns 낮은 최대잔차폭을 가지며, 이는 제안한 모델이 수소메이저의 시계열 예측에서 통계 기반의 ARIMA 모델의 한계인 예상치 못한 수소 메이저의 홀드오버 상황에 효과적으로 대응함을 의미한다. 이는 시각 동기화 기술의 정확도와 신뢰성을 크게 향상시킬 것으로 기대된다.
이 성과는 정부 (과학기술정보통신부)의 재원으로 한국표준과학연구원 (KRISS)의 지원을 받아 수행된 연구임 (국제단위계(SI) 재정의 선도 차세대 측정표준 연구).
Conceptualization, DH Yu and YK Lee; methodology, DH Yu; software, SJ Kim; validation, DH Yu and YK Lee; formal analysis, JH Rhee and JI Oh.; investigation, SJ Kim; resources, J Lee; data curation, GW Choi.; writing—original draft preparation, SJ Kim; writing—review and editing, SJ Kim; project administration, YK Lee.
The authors declare no conflict of interest.
Gui, J., Chen, T., Zhang, J., Cao, Q., Sun, Z., et al. 2023, A Survey on Self-supervised Learning: Algorithms, Applications, and Future Trends. https://doi.org/10.48550/arXiv.2301.05712
Kanhere, A. V., Gupta, S., Shetty, A., & Gao, G. 2022, Improving GNSS Positioning using Neural Network-based Corrections. https://doi.org/10.48550/arXiv.2110.09581
Lee, H.-S., Kwon, T.-Y., Lee, Y.-K., Yang, S-H., & Yu, D.-H. 2020, Prediction of Hydrogen Masers’ Behaviors Against UTCr with R, Journal of Positioning, Navigation, and Timing, 9, 89-98. https://doi.org/10.11003/JPNT.2020.9.2.89
Ozeki, T. & Kubo, N. 2022, GNSS NLOS Signal Classification based on Machine Learning and Pseudorange Residual Check, Frontiers in Robotics and AI, 9, Article 868608. https://doi.org/10.3389/frobt.2022.868608
Piccolomini, E. L., Gandolfi, S., Poluzzi, L., Tavasci, L., Cascarano, P., et al. 2019, Recurrent Neural Networks Applied to GNSS Time Series for Denoising and Prediction, 26th International Symposium on Temporal Representation and Reasoning (TIME 2019), vol.147, pp.10:1-10:12. https://doi.org/10.4230/LIPIcs.TIME.2019.10
Semanjski, S., Semanjski, I., De Wilde, W., & Muls, A. 2020, Use of Supervised Machine Learning for GNSS Signal Spoofing Detection with Validation on Real-World Meaconing and Spoofing Data—Part I, Sensors, 20, 1171. https://doi.org/10.3390/s20041171
Shahvandi , M. K. & Soja, B. 2021, Modi f ied Deep Transformers for GNSS Time Series Prediction, 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, 11-16 July 2021, Brussels, Belgium. https://doi.org/10.1109/IGARSS47720.2021.9554764
Yu, D. 2017, Comparison of Clock Solution of GLONASS Time Transfer Using ESOC Clock Products, International Journal of Control and Automation, 10, 199-208. https://doi.org/10.14257/ijca.2017.10.1.18
Yu, D. & Hwang, S. 2018, Design of Simulator for Time Comparison and Synchronization Method Between Ground Clock and Onboard Clock, Advanced Multimedia and Ubiquitous Engineering. MUE FutureTech 2018. Lecture Notes in Electrical Engineering, vol.518 (Singapore: Springer). https://doi.org/10.1007/978-981-13-1328-8_65
Yu, D. & Kim, M. 2022, Deep Learning based Time Offset Estimation in GPS Time Transfer Measurement Data, Journal of the Korea Institute of Information and Communication Engineering, 26, 456-462. https://doi.org/10.6109/jkiice.2022.26.3.456